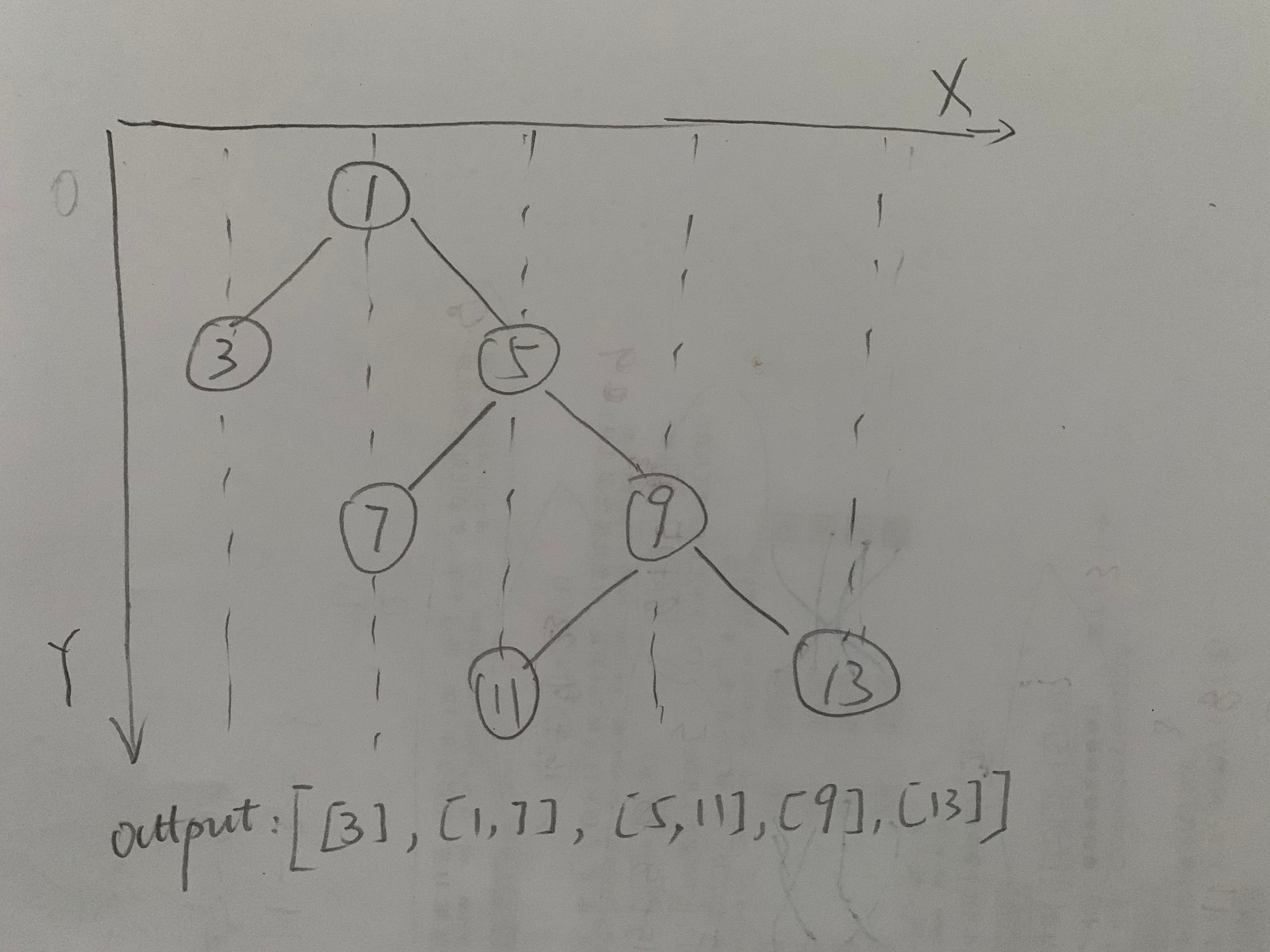
Given a binary tree, return the vertical order traversal of its nodes values.
For each node at position (X, Y), its left and right children respectively will be at positions (X-1, Y-1) and (X+1, Y-1).
Running a vertical line from X = -infinity to X = +infinity, whenever the vertical line touches some nodes, we report the values of the nodes in order from top to bottom (decreasing Y coordinates).
If two nodes have the same position, then the value of the node that is reported first is the value that is smaller.
Return an list of non-empty reports in order of X coordinate. Every report will have a list of values of nodes.
As the graph for above example shows, it is actually asking for one thing: output all Y values (from smallest to largest) by X value from smallest to largest.
Since Y axis’s direction is downward, it will be natural to visit the tree to top to down layer by layer, taking notes of nodes’ values in a manner of {x: node’s value} (for example, for the second layer, I will have {-1:[3], 1:[5]} meaning for x = -1 in this layer, there is a node with value [3]). One tricky thing is that if in a specific layer, if there are 2 nodes in the same X values, a smaller value is required to be ahead of a larger one). While visiting current layer nodes, I can in the same time storing each node’s left and right children nodes to prepare for next layer’s visit.
Finally, when I finish visiting all layers, I should have a dictionary like {x0 : [[y1,y2],[y3]], x2:[[y2]],x1:[[y1,y4],[y5]]}, since the required output asks for left to right order, I will sort the keys (x0,x2,x1) and then add each key’s value to return result.
The whole solution is pretty straightforward. But it actually requires a clear understanding of what I’m doing especially in the middle of programming and appropriate use of multiple data structures. Therefore, it can be very error prone. For myself, I actually forgot to reset nodesInNextLayer to an empty list after finish visiting a layer and it took me like 10 minutes to figure out that. For those details, I will cover them inline in below codes.
Time & Space Complexity
With above solution, there are 3 parts needed to take into consideration when concluding time complexity:
I need to visit each and every node once to gather its X/Y coordinates and for this part time complexity is O(N).
Within the visit of each layer, there will have some sorting occurring which can take O(MlogM) assuming average M collisions for the same (x,y). M is directly related to N so I can say this is O(NlogN).
Now for the third part: before I return the res where I will sort d.keys(), the more nodes the input has, normally the more X values would be so that part will take O(NlogN).
In conclusion, the sum of time complexity will be O(NlogN).
I use several dictionaries and lists but their sizes are scaling in the same level as input size (N) so total space complexity is O(N).
Python 3 knowledge points
Basic data structures like tuple, dictionary, list. Please refer to my Python3 cheatsheet.
Photo by Pablo Hermoso on Unsplash Problem Description Given n non-negative integers representing the histogram’s bar height where the width of each bar is 1, find the area of largest rectangle in the histogram. Above is a histogram where width of each bar is 1, given height = [2,1,5,6,2,3] . The largest rectangle is shown in the shaded area, which has area = 10 unit. Example: Input: [2,1,5,6,2,3] Output: 10 Solution Obvious Solution The obvious (and brute force) way is to use 2 pointers: left and right. Let left points to index 0 ~ N-1 and then right to left and N-1. For each left and right pair, I can calculate the area[left, right] using (right-left+1) * min(heights[left], heights[left+1],heights[left+2],…,heights[right]). Its time complexity is at least be O(N²). Best Solution (to me) [Credit] This is described by @ TravellingSalesman in disucssion area ( https://leetcode.com/problems/largest-rectangle-in-histogram...
Problem Description Given a sorted array A of unique numbers, find the K -th missing number starting from the leftmost number of the array. Example 1: Input: A = [4,7,9,10] , K = 1 Output: 5 Explanation: The first missing number is 5. Example 2: Input: A = [4,7,9,10] , K = 3 Output: 8 Explanation: The missing numbers are [5,6,8,...], hence the third missing number is 8. Solution Seeing the word " sorted " reminds me that there must be some trick to play with. One common thought of mine is binary lookup , which is used for quickly, in O(logN), to locate a specific element. And it turns out similar thoughts applies to this problem as well. Before getting to that, let me explain the brute force way a little bit. First I need to set a counter to count missing number I find as of now, in the beginning, it will be 0 for sure. Then I can certainly iterate the numbers one by one, the moment I get to index i, I will check if A[i] is the last elemen...
Photo by Ricky Kharawala on Unsplash Problem Description Given a non-empty, singly linked list with head node head , return a middle node of linked list. If there are two middle nodes, return the second middle node. Example 1: Input: [1,2,3] Output: Node 2 from this list (Serialization: [2,3]) The returned node has value 3. (The judge's serialization of this node is [2,3]). Example 2: Input: [1,2,3,4] Output: Node 3 from this list (Serialization: [3,4]) Since the list has two middle nodes with values 2 and 3, I return the second one. Solution There are basically 2 ways to tackle this problem. One is obvious to scan the link twice: the first time to get the total number of nodes, then I can divide it by 2 to get the middle index, a second scan will be run to find the middle index to return. The other way to do it is using one time scan: I can use 2 movers (fast and slow ones), in each iteration, slow mover will only move to the next node w...





Comments
Post a Comment