Leet Code 82. Remove Duplicates from Sorted List II — Graphically Explained Python3 Solution

Problem Description
Given the head of a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numbers from the original list. Return the linked list sorted as well.
Example 1:
Input: 1->1->2->2
Output: <empty>
Example 2:
Input: 1->2->2->3
Output: 1->3
Solution
The most fun (or puzzling) part of this problem is: when you come to a node that is different in value with its previous one, you don’t know whether it’s a duplicate one until you go to its next node.
To me, there is a pattern here: during an iteration, I cannot make a decision on current element before I get to following elments. Normally I can use stack for this pattern. The key is: somehow I store elements in stack (so that I can retrieve them in a reversed or original order) for now and fetch them later basing on situations.
So assume I have an input linked list like:

Step by step walk-through
- When I iterate the list using a pointer (p) and first I see “1” in the beginning. Since I don’t know whether there will be more ‘1’ along the road (yet), I will just put it in the stack.

2. Now I move p to the second node and I see another “1”. This time I actually know “1” is duplicate but in case there are more “1” following, I will just throw it into the stack as well.

3. Here p points to the third node “2”, since it’s not equal to the top item of the stack (which is “1” as shown in previous step) and this is an ascending linked list, I know a duplication list of “1” ends so I will just clear the stack. And for current node “2”, again I don’t know whether it’s duplicate so I have to push it to the stack.
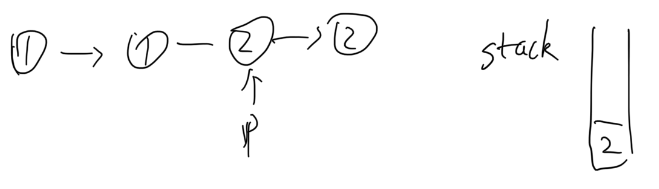
4. Like #2, I add the last node to the stack and move p to its next.
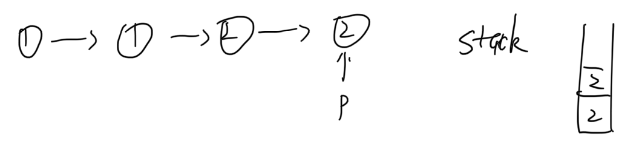
5. Finally I reach the end of input linked list and since the stack contains more than 2 elements (and for sure they have duplicate values), I will discard them as well. In the end, I will return an empty list (None in Python).
Another tip: a dummy header
In above example, there is actually nothing left in the result. Consider another example 1->2->2->3, similiarly, when I visit the second node which has a different value than stack[-1] and len(stack) == 1, it means the one in the stack is a unique one, I need to put it in final result link. A little tedious handling is: normally I need to see if this unique one is the first unique one and write separate codes to tackle yes/no situations like:
if len(stack)==1 and stack[-1].val != p.val:
if resultHeader == None:
resultHeader = stack.pop()
preNode = resultHeader
else:
preNode.next = stack.pop()
preNode = preNode.next
....
#finally return resultHeader
return resultHeader
It would be beautiful if I can use the same set of codes for both situations! And actually there is a way like:
resultHeader = ListNode() #this is a dummy header
preNode = resultHeader
if len(stack)==1 and stack[-1].val != p.val:
preNode.next = stack.pop()
preNode = preNode.next
....
#finally return resultHeader.next
return resultHeader.next
Source Code
Time & Space Complexity
All nodes will be visited once so time complexity is O(N). Stack may contain all nodes in worst case (for example, all elements are distinct) and in that case, space complexity will be O(N).
Extended Reading
Python3 cheatsheet:
https://medium.com/@edward.zhou/python3-cheatsheet-continuously-updated-66d652115549
Comments
Post a Comment